Predicting mental health and substance use in adulthood from resilience in adolescence
Project Summary: Bayes. Mediation. Lots of data.
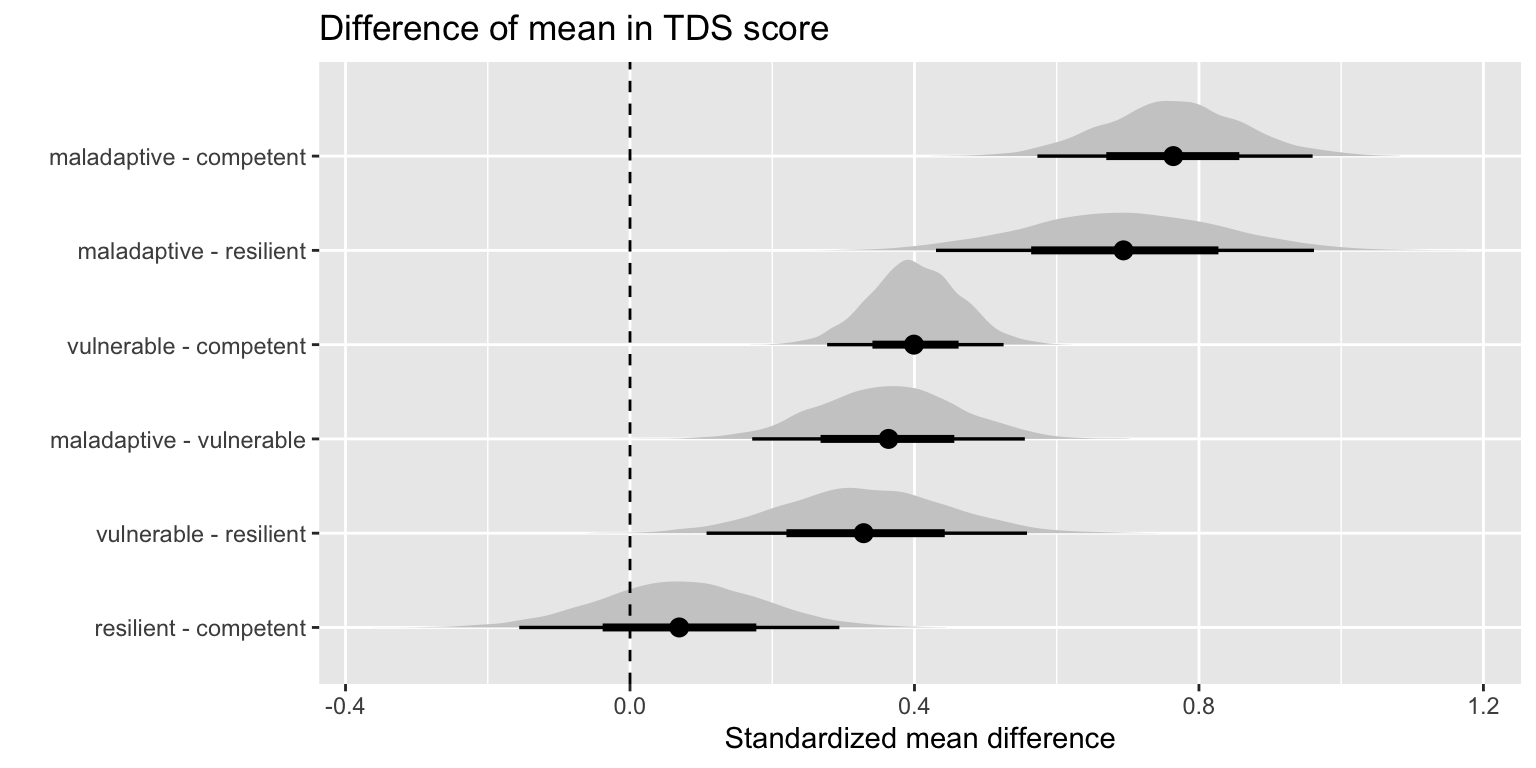
In this study I use data from the IMAGEN Study (initial n=2315) to determine if mental health and drug use in adulthood (~age 23) can be predicted by resilience in early adolescence (~age 14). Adolescents are classified into one of four groups following Burt et al’s operationalization of resilience as the interaction between competence and adversity. In addition, I look at whether structural brain differences at age 14 in brain regions identified by Burt mediate any of the differences observed in mental health outcomes and alcohol use at age 23.
To summarize, I find that there are significant differences in mental health outcomes and recent drug use at age 23 between the four groups. Additionally, the gray matter volume differences identified between the groups at age 14 did not mediate any of the differences in mental health or drug use. These results suggest that developmental features of early resilience such as social skills interact with adversity in a positive way and are predictive of numerous outcomes in adulthood. This corroborates with findings by (Roisman et al. 2004) that suggest the importance of developmentally salient tasks in predicting adult success.
View the rest of the interact report here.